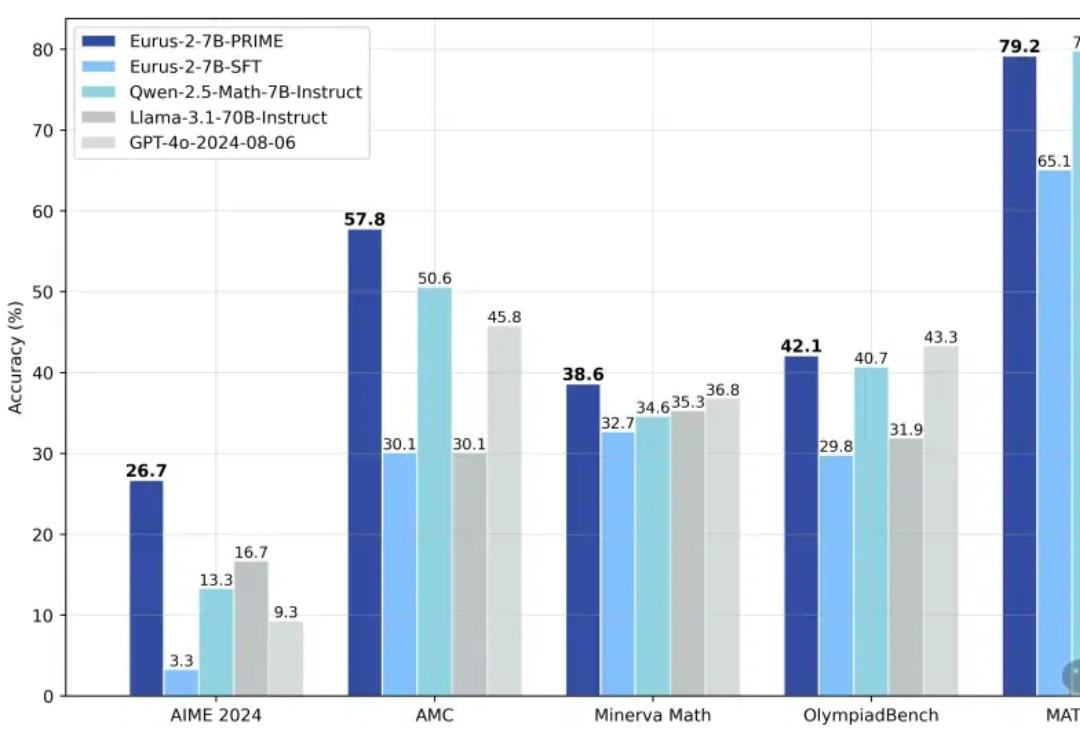
仅需一万块钱!清华团队靠强化学习让 7B模型数学打败GPT-4o
仅需一万块钱!清华团队靠强化学习让 7B模型数学打败GPT-4oOpenAI o1和o3模型的发布证明了强化学习能够让大模型拥有像人一样的快速迭代试错、深度思考的高阶推理能力,在基于模仿学习的Scaling Law逐渐受到质疑的今天,基于探索的强化学习有望带来新的Scaling Law。
来自主题: AI资讯
7658 点击 2025-01-06 14:56
 搜索
搜索
OpenAI o1和o3模型的发布证明了强化学习能够让大模型拥有像人一样的快速迭代试错、深度思考的高阶推理能力,在基于模仿学习的Scaling Law逐渐受到质疑的今天,基于探索的强化学习有望带来新的Scaling Law。
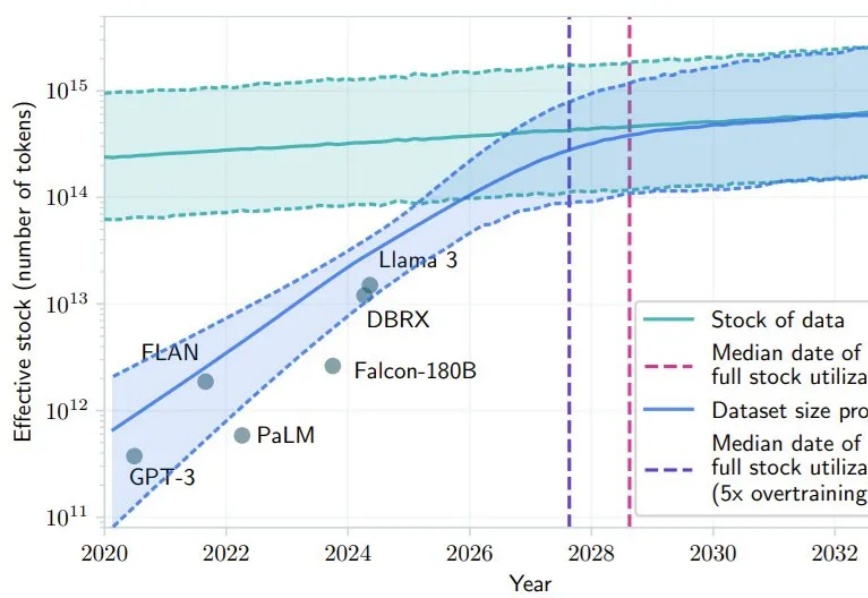
最近 AI 社区很多人都在讨论 Scaling Law 是否撞墙的问题。其中,一个支持 Scaling Law 撞墙论的理由是 AI 几乎已经快要耗尽已有的高质量数据,比如有一项研究就预计,如果 LLM 保持现在的发展势头,到 2028 年左右,已有的数据储量将被全部利用完。

过去一段时间,“预训练终结”成为了 AI 领域最热烈的讨论之一。OpenAI的GPT系列模型此前大踏步的前进,预训练是核心推动力。而前 OpenAI 首席科学家 Ilya Sutskever、预训练和scaling law(规模定律)最忠实的倡导者,却宣称预训练要终结了、scaling law要失效。由此,引发了大量争议。

在 2024 年的 NeurIPS 会议上,Ilya Sutskever 提出了一系列关于人工智能发展的挑战性观点,尤其集中于 Scaling Law 的观点:「现有的预训练方法将会结束」,这不仅是一次技术的自然演进,也可能标志着对当前「大力出奇迹」方法的根本性质疑。
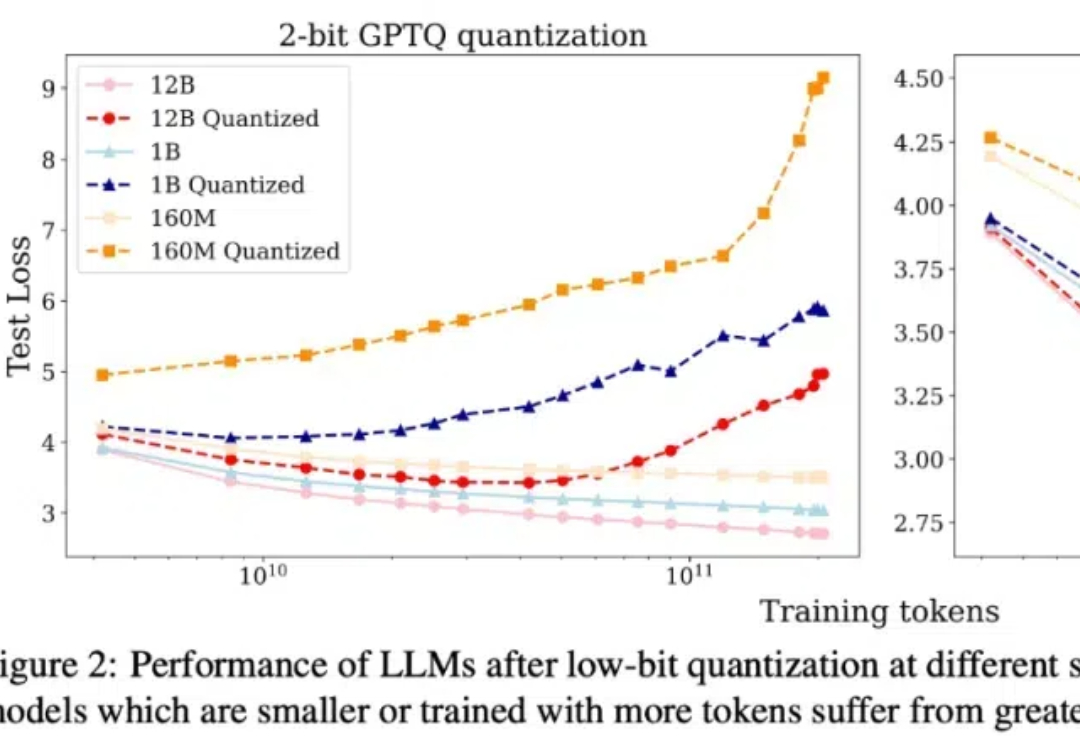
本文介绍了一套针对于低比特量化的 scaling laws。
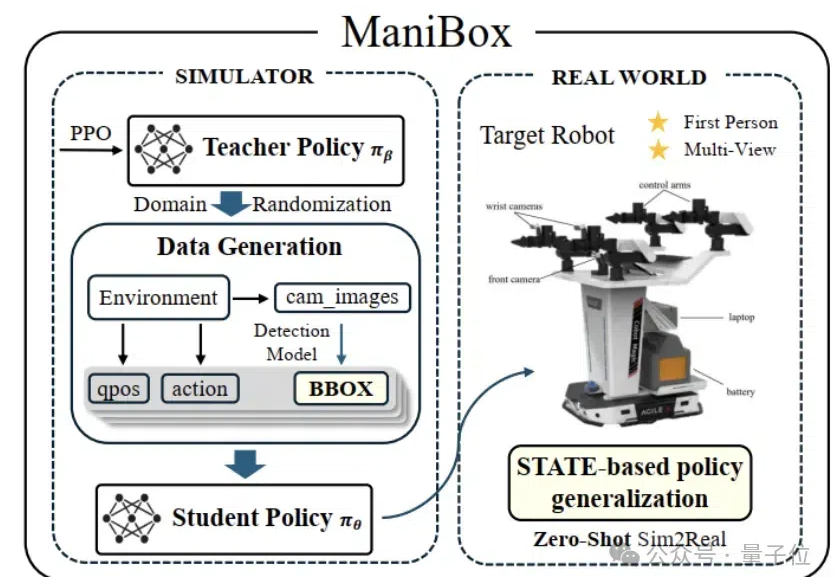
在机器人空间泛化领域,原来也有一套Scaling Law! 来自清华和新加坡国立大学的团队,发现了空间智能的泛化性规律。 在此基础上,他们提出了一套新颖的算法框架——ManiBox,让机器人能够在真实世界中应对多样化的物体位置和复杂的场景布置。

在营销应用赛道也有类似Scaling Law的规则—— 当营销素材工业化生产的时候,不断提升生产效率,就能产生爆款。
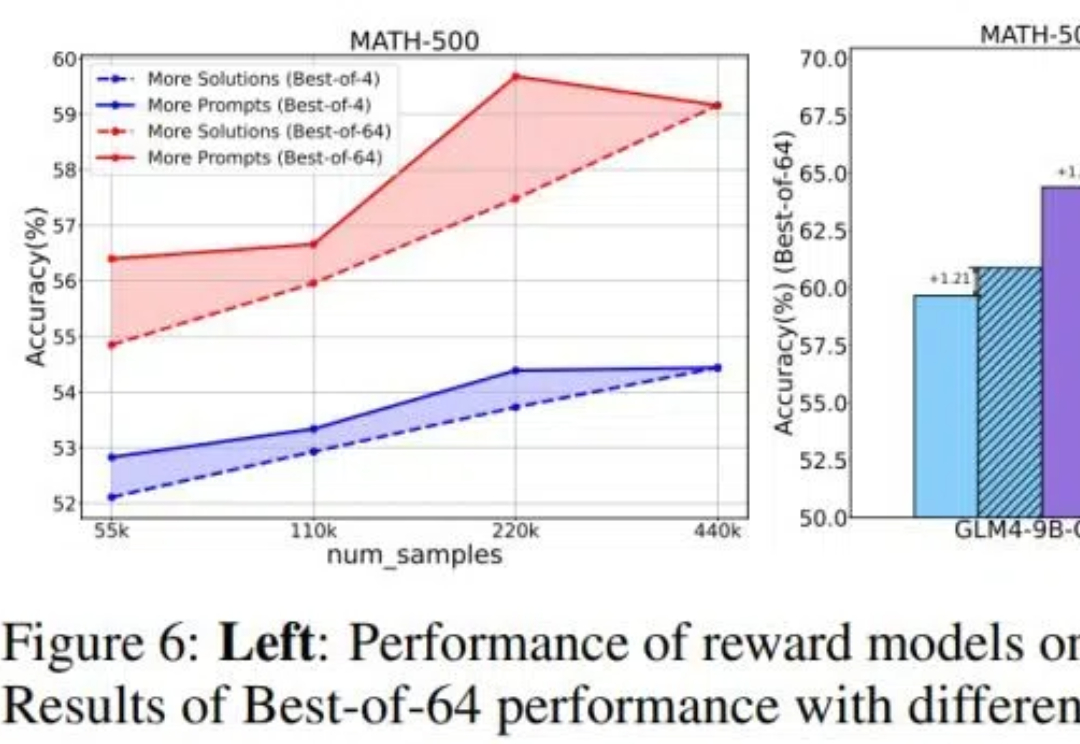
目前关于 RLHF 的 scaling(扩展)潜力研究仍然相对缺乏,尤其是在模型大小、数据组成和推理预算等关键因素上的影响尚未被系统性探索。 针对这一问题,来自清华大学与智谱的研究团队对 RLHF 在 LLM 中的 scaling 性能进行了全面研究,并提出了优化策略。
不像西部世界的 AI 那么智能,现在的 AI 经常没办法满足我的小众需求。 我开始以为是模型能力的问题,但是试用了各家的 AI 发现它们都因为使用的搜索引擎 API 无法搜出相关内容而无法解答。

12 月 2-6 日,亚马逊云科技在美国拉斯维加斯举办了今年度的 re:Invent 大会。会上,亚马逊云科技发布了相当多东西,其中之一便是新的大模型系列 Nova。说实话,这确实出乎了相当多人的意料 —— 毕竟亚马逊已经重金押注 Anthropic,似乎没有必要再自起炉灶了。